Database design is becoming key to developing applications. Almost all web applications are driven by a database, and with Core Data, Cocoa applications are starting to have true database back ends. Therefore it is surprising that so many programmers dont know anything about database design. So here is a simple overview of the theory behind database design.
What is the benefit of using a database? Well, for one, it is fast. If you were using XML file stores for lots of data then you will know just how slow they are. SQL is much faster as it only loads the data that is needed. Another benefit is data redundancy, or rather the lack of it in a well designed database. There are 3 main bits of database design that I am going to go through: keys, relationships and normalisation. The first two are very simple, but normalisation is a little hard to get your head round at first, but it is fundamental to a well designed database, both in terms of speed and redundancy.
Terminology
First off, lets get the basic terminology out of the way. A database is a central pool of data, simple as that. Within a database there can be several tables. A table (or entity) is a subset of this data, e.g. a customer or a sale. Think of a table as a spreadsheet. Each table has attributes and rows. An attribute is a piece of data, e.g. a customers name, email, phone number etc, where as each row is an instance of data, e.g. Fred Blogs, fred@example.com, 01234 567890.
So many keys but no locks for miles
One of the most important things a database needs is a key, or more precisely a Primary Key. This is a unique identifier for a row and is needed to be able to access data in a table. In Core Data this is taken care of automatically, however you will have to deal with them yourself in other databases. A Primary Key can be made up of more than one field, e.g. customer name and phone number, in which case it is a Concatenated Key.
A Foreign Key is used when linking two tables together in a relationship. A Foreign Key is simply a Primary Key from another table, allowing you to associate elements from one table to another. For example, each sale would have a foreign key customer id, which would relate to the customer who purchased goods in the sale.
Relationships, the sort without anniversaries
Relationships are key to reducing data redundancy. As the name suggests, its how data relates to other data within your database. The above example of customers and sales is a relationship. Relationships are formed between rows in two tables and come in 3 types, only two of which are feasible in a database:
* One-to-One: A one-to-one relationship is where one row in table A relates to just one row in table B. If table A was a table of bodies and table B was a table of heads, then each head has one body (unless you are president of the universe).
* One-to-Many: A one-to-many relationship is where one row in table A relates to just as many rows in table B. If table A was our table of bodies and table B was a table of arms, then each body would have many arms.
* Many-to-Many: This is the odd one out. Databases cant deal with many-to-many relationships. If you had a table of objects and a table of colours, an object can have many colours, but a colour can be on many objects. However, there are ways around this.
Relationships work in a tree structure such that you can go from one object to many and then go back to just that one object. If you go from objects to colours you might get to blue. However if you go back from blue you do not go back to that single object, but a wide range of objects. As such you need to add a table in between, which will contain a list of all object colours. This may only contain foreign keys for colourID and objectID, but these would be concatenated primary keys.
Normalisation
Normalisation is the process of taking a set of data and converting it to its most efficient form. As of 2005 there are 6 normal forms (NF), though only the first 3 are relevant to the majority of databases. Im going to take you through the process of normalising a database to 3rd Normal Form (3NF). Lets take a look at a simple set of data:
| CustomerID | CustomerName | Email | SaleID | DateOfPurchase | Quantity | ... |
|---|
| 1 | Fred Blogs | fred@example.com | 1 | 11/12/06 | 3 | ... |
| | | | | 1 | ... |
| | | 3 | 24/12/06 | 1 | ... |
| 2 | Jane Doe | jane@example.com | 2 | 12/12/06 | 2 | ... |
| | | 4 | 24/12/06 | 1 | ... |
| AppID | AppName | Price | Code | Version |
|---|
| 1 | CoolApp | 25 | 123456 | 1 |
| 2 | HotApp | 15 | 01264 | 1 |
| 1 | CoolApp | 25 | 458746 | 2 |
| 2 | HotApp | 15 | 66594 | 1 |
| 1 | CoolApp | 25 | 458746 | 2 |
This would be something you would typically find in a spreadsheet. Unfortunately this isnt at all normalised. In order to be fit for a database your data needs to be at least in 1NF:
1NF - Remove any repeated fields
Often going from a data set, such as a spreadsheet, to 1NF increases data redundancy, though this is required to work in a database. You cannot have blank fields in a row and expect the database to know that it should look up till it finds the next row with data. Like with most things regarding computers, they arent as smart as humans. So the first job is to remove any repeated fields and assign a primary key to each row. This would give us a table like so:
| CustomerID | CustomerName | Email | SaleID | DateOfPurchase | Quantity | ... |
|---|
| 1 | Fred Blogs | fred@example.com | 1 | 11/12/06 | 3 | ... |
| 1 | Fred Blogs | fred@example.com | 1 | 11/12/06 | 1 | ... |
| 1 | Fred Blogs | fred@example.com | 3 | 24/12/06 | 1 | ... |
| 2 | Jane Doe | jane@example.com | 2 | 12/12/06 | 2 | ... |
| 2 | Jane Doe | jane@example.com | 4 | 24/12/06 | 1 | ... |
| AppID | AppName | Price | Code | Version |
|---|
| 1 | CoolApp | 25 | 123456 | 1 |
| 2 | HotApp | 15 | 01264 | 1 |
| 1 | CoolApp | 25 | 458746 | 2 |
| 2 | HotApp | 15 | 66594 | 1 |
| 1 | CoolApp | 25 | 458746 | 2 |
We can make a primary key for the row by concatenating SaleID and AppID, Each Sale will only have each App listed once, as such makes a good primary key as we are guaranteed it will always be unique. Unfortunately, as I pointed out, we have introduced quite a lot of data redundancy that wasnt previously there. To start to remove this we are going to have to take the database to 2NF.
2NF - Remove all partial dependencies on the Concatenated Key
The phrasing above always confused me with database design, so heres the simpler form: move any fields that arent dependent on both of the fields that make up the concatenated keys into new tables. If it still doesnt make sense, dont worry. Doing it is often better than thinking about it. Here is our table in 1NF:

Now we need to see what fields rely on both the SaleID and AppID:
* CustomerID, CustomerName and Email dont depend on either key, so we can ignore those for now.
* The DateOfPurchase relies on the sale, but not the application; an application can be purchased on many dates, but a sale occurs once.
* AppName obviously is based on the application.
* Quantity relies on the sale; different sales can have different quantities. However, different apps within a sale can have different quantities. As such this is based on both keys.
* The Price and Version of the application are not related to the sale so are grouped with the application.
* And finally, the Code is based on the application and the sale.
Now that we have worked out what is related to what, lets look again at our table in 1NF. Fields relating to AppID are in red, SaleID are in green, both keys are in blue and neither key are in grey.

Our next job is to take all of the fields relating in any way to the 2nd half of the concatenated key and put them in a new table. As such we take those fields depending on just the AppID (AppName, Price, Version) and those depending on the concatenated key (Quantity, Code) and move them to a new table. This table is usually named based on the two entities that make up the key, in this case it will be Sale_Apps. Our original table will be called Sales.
NB: Some readers have been asking why the Customer fields arent moved. The reasoning behind this is that they arent dependent on any key. As such we leave them where they are. We want to find what fields relate to what key. In this first stage we are just moving those that depend on both keys or only the 2nd part of the concatenated key to a new table. Those that depend on only the first part or neither key get left alone:
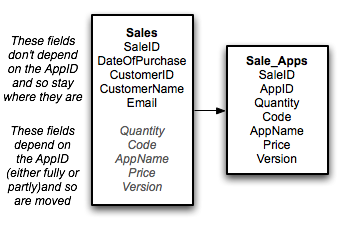
Our database now looks like this:
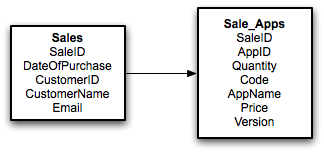
Arrows point one to many, with the arrowhead being the many side. As such a Sale may have many Sale_Apps. Of course this database is not completely normalised to 2NF. Remember that we have to move any fields that dont rely on both keys of the concatenated key for their value to a new table. As we showed before, AppName, Price and Version are dependent only on AppID. As such we need another table:
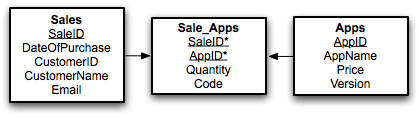
This is our table, fully normalised in 2NF. Now there are two points I would like to make. The first is that I have added notation to signify primary and foreign keys. As with all notation, there are several ways for showing things, though I will show you the way I was taught. All primary keys are underlined and/or made bold. As I am making my table names bold, I have decided to underline my primary keys. Foreign keys are denoted by an asterisk. In the above case you will notice that both parts of the concatenated key in Sale_Apps are foreign keys, but together are also the primary key for the table.
The second thing I would like to point out is that this is a good example of getting around many-to-many relationships. A Sale can have many Apps, yet an App can have many Sales. As such you need the Sale_Apps table to provide unique pairings for each combination. The simple way to get around a many to many situation is to put a 3rd table in the middle, put both primary keys in as a concatenated key and reverse the direction of the arrows (so that the to many goes to the new table).
3NF - Remove all dependencies on non key attributes
While our database looks much better than when we started, there is still room for improvement. This 3rd stage is often the most efficient stage for your database. It is little more than cleaning up the loose ends, as much of the hard work was done in getting the database to 2NF. In this stage we move all fields not explicitly dependent on the primary key of a table to another table. This often requires looking at your end tables as your middle table is usually already in 3NF. So lets look at Sales. The DateOfPurchase is explicitly tied to the SaleID, each sale has its own date of purchase. However a Customer is not tied to the SaleID, a Customer has many Sales but a Sale has one Customer, so the fields relating to a customer can be moved to another database.
NB: Some of you might be asking, But cant a date have many sales, but a sale one date?. Yes this is true and if we are being truly picky we could put this into another table. However, this would increase the size of the database. You are having to add a new table, with a primary key and a foreign key and a relationship between the two tables. You have to use your brains to work out what would be better. There are cases when taking out one field can be a benefit, if it means many other fields would have to be duplicated to change just one value, for example.
Here is our database with the customers taken out:
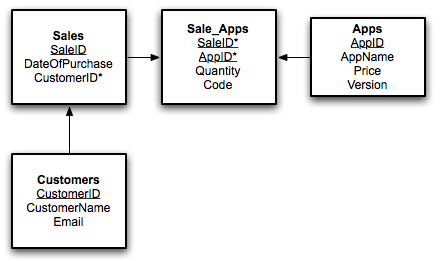
This is our normalised database. We could, if we wanted, separate the version and the price into a separate table, but that would require much more work and make things more complicated than they need to be. Which brings me to my last point about normalisation. Dont over normalise just because you want to have as little data redundancy as possible. A completely normalised database may in fact be a disadvantage by being harder to work with than a partially normalised database.
So lets go back to our tables and see what our data now looks like in our database:
Customers
| CustomerID | CustomerName | Email |
|---|
| 1 | Fred Blogs | fred@example.com |
| 2 | Jane Doe | jane@example.com |
Sales
| SaleID | DateOfPurchase | CustomerID* |
|---|
| 1 | 11/12/06 | 1 |
| 2 | 12/12/06 | 2 |
| 3 | 24/12/06 | 1 |
| 4 | 24/12/06 | 2 |
Sale_Apps
| SaleID* | AppID* | Quantity | Code |
|---|
| 1 | 1 | 3 | 123456 |
| 1 | 2 | 1 | 01264 |
| 3 | 1 | 1 | 458746 |
| 2 | 2 | 2 | 66594 |
| 4 | 1 | 1 | 458746 |
Apps
| AppID | AppName | Price | Version |
|---|
| 1 | CoolApp | 25 | 1 |
| 2 | HotApp | 15 | 1 |
| 3 | CoolApp | 25 | 2 |
As you can see, we have greatly reduced the amount of data redundancy in our database. In the process weve also allowed for much more interesting tests to be performed (such as how many copies of CoolApp 1 were sold between the 10th and 20th of December). Hopefully this post has given you enough to get started with making good databases, have fun!